
I use ImageMagick to do some simple processing of photos I take on my DSLR. Originally it was shell scripts that use find, xargs (using the parallel option,) and mogrify with an awk script to generate a trival HTML table. I rewrote this in Python using the WARD API library for ImageMagick and decided to check how they stacked up.
The process makes 3 copies of each picture. The first is full size with auto-orientation (rewrites it to be upright even if the displaying program doesn’t understand the orientation coded in EXIF.) The next is that plus 33% of original size. The last is a 10% thumbnail.
I decided to run 1 through 12 parallel processes/threads and track the time. I knew the Python approach was faster but wanted some data. I’ll note up front that this isn’t scientific. There were a number of uncontrolled variables on the system and that is certainly the reason for any variation in the numbers beyond 6 parallel.
The machine for this was my desktop, running Linux Mint 19 on an ASUS VivoMini VC66 that has an i5 quad core CPU and 24GB of ram. The source for the images was the compactflash (CF) card from the camera in a USB 3.0 reader and the output was written to the 1 TB M.2 SSD drive. There were 363 images from a local drag king show on the card.
A couple notes on source media: My camera is a Nikon D800 which has both CF and SD card slots. I use both and have it set to backup, meaning it writes each image to both cards. I did test going from SD but found worse performance. From the USB 3.0 reader I found a copy of 6.9GB of images from the CF card took 66 seconds. The SD card in the same reader was 90 seconds for the name brand and 113 for a generic. The VC66 has a built in reader for SD cards but it’s even slower, taking 255 seconds with the generic; I didn’t try the name brand in that.
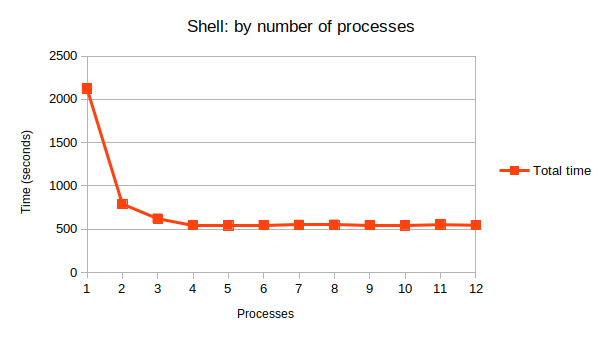
First, here’s the data for the existing shell scripts. It plateaus completely at 4 simultaneous images. Iterations for more than 5 parallel are omitted; all are within 1% of the time and are most likely other processing load on the system.
| Shell Threads | Total time | Time per image |
| 1 | 2124.82 | 5.85 |
| 2 | 790.307 | 2.18 |
| 3 | 621.039 | 1.71 |
| 4 | 545.675 | 1.50 |
| 5 | 543.927 | 1.50 |
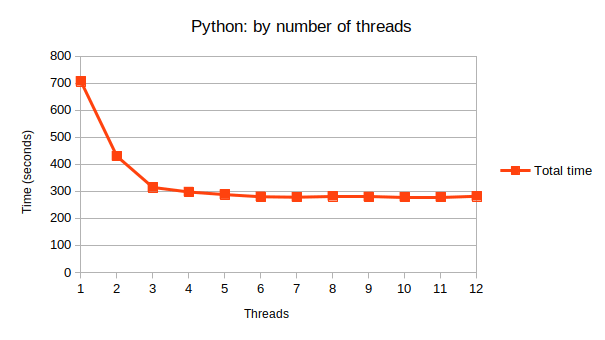
Python data shows some big gains until 3 images, then decreasing gains until 6. Data after 7 is omitted as it’s the same sort of 1% variation as mentioned above.
| Python Threads | Total time | Time per image |
| 1 | 706.73 | 1.95 |
| 2 | 429.85 | 1.18 |
| 3 | 314.44 | .87 |
| 4 | 297.53 | .82 |
| 5 | 287.85 | .79 |
| 6 | 279.92 | .77 |
| 7 | 278.18 | .77 |
The only situation where Python isn’t outperforming shell is 1 Python thread vs 4 parallel via the shell script. Even 2 threads in Python is faster than the best of the shell script.
My fiancée asked if more cores would help. The way the gains stacked up against core count made me doubtful and I decided to check into other factors. M.2 SSD transfer speeds are definitely not the limitation. USB 3.0 isn’t, either. However, the CF card is. It’s rated for 120MB/s and with a mean average of 20MB per image then 6 hits this.
And this is where a lot of difference in time comes from. My shell script re-read each image on the source media for each operation, so n*3 reads from the media, or 1089 for this experiment. With Python it’s n reads. My guess is that’s most of the performance difference.
I’ll leave you with the graphs. Mostly they show that the curve is very similar.

You must be logged in to post a comment.